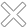
SQL Server Big Data Clusters provides a deployment of scalable SQL Server clusters, Spark, and HDFS containers running on Kubernetes. These components run in parallel, allowing you to read, write and process big data in Transact-SQL or Spark, so you can easily merge and analyse important relational data with voluminous big data.
This is an article for experienced developers. Learn more about what is web hosting and why it is important previously.

The Controller provides cluster management and security. It includes the control service, configuration repository, and other cluster-level services such as Kibana, Grafana, and Elastic Search.
The compute pool provides compute resources to the cluster. It contains nodes with a SQL Server pod on Linux. Pods in the compute pool are subdivided into SQL compute instances for specific processing tasks.
The data pool is used to store data. The data pool consists of one or more SQL Server pods on Linux. It is used to receive data from SQL queries or Spark jobs.
A media pool is formed from a pod pool of media consisting of SQL Server on Linux, Spark and HDFS. All storage nodes in the SQL Server big data cluster are part of the HDFS cluster.
Application Deployment allows you to deploy applications in SQL Server Big Data Clusters, providing interfaces for creating, running, and managing applications.
SQL Server Big Data Clusters provide high flexibility when working with big data. You can query external data sources, store big data in HDFS under SQL Server control, and query data from multiple external data sources through a cluster. The resulting data can be processed using artificial intelligence, machine learning, and other analytical techniques.
Use SQL Server big data clusters for the following tasks:
Ensure high availability for the main SQL Server instance and all databases using Always On availability group technology.
The following subsections contain more information about these scenarios.
With PolyBase, SQL Server Big Data Clusters can query external data sources without having to move or copy data. SQL Server 2019 (15.x) includes new connectors for data sources. For more information, see New PolyBase 2019 features.
SQL Server big data cluster includes a scalable HDFS media pool. It can be used to store big data that can come from multiple external sources. Once you store big data in HDFS in the big data cluster, you can analyse and query it and merge it with relational data.
SQL Server big data clusters allow you to perform artificial intelligence and machine learning tasks on data stored in HDFS data pools and media pools. You can use Spark as well as artificial intelligence-based tools built into SQL Server that use R, Python, Scala or Java.
Management and monitoring capabilities are implemented through a combination of command line tools, APIs, portals, and dynamic administrative views.
You can use Azure Data Studio to perform a variety of tasks in a big data cluster.
A data virtualization wizard that simplifies the process of creating external data sources (enabled with the Data Virtualization extension).
SQL Server Big Data Cluster is a cluster of Linux containers running Kubernetes.
Kubernetes is an open-source container orchestrator that provides scalable container deployments according to needs.
A Kubernetes cluster is a set of computers, also called nodes. One node is used to manage the cluster and is the main node. The other nodes are considered to be worker nodes. The Kubernetes master node is responsible for distributing the workload among the worker nodes and also for monitoring the health of the cluster.
The node runs the container applications. This can be either a physical computer or a virtual machine. A Kubernetes cluster can include nodes of both physical computers and virtual machines.
A Pod is an atomic unit of a Kubernetes deployment. A Pod is a logical group that consists of one or more containers and associated resources needed to run an application. Each pod runs on a node. In doing so, a node can execute in one or more pods. The Kubernetes master node automatically assigns existing pods to nodes in the cluster.
In SQL Server Big Data Clusters, the Kubernetes service is responsible for the state of the cluster. To perform this task, Kubernetes creates and configures cluster nodes, assigns existing pod modules to them, and monitors the health of the cluster.
